Performance & Comparison


Per-category FID on MJHQ-30K
Efficiency & CLIP-Score of 512x512 generation
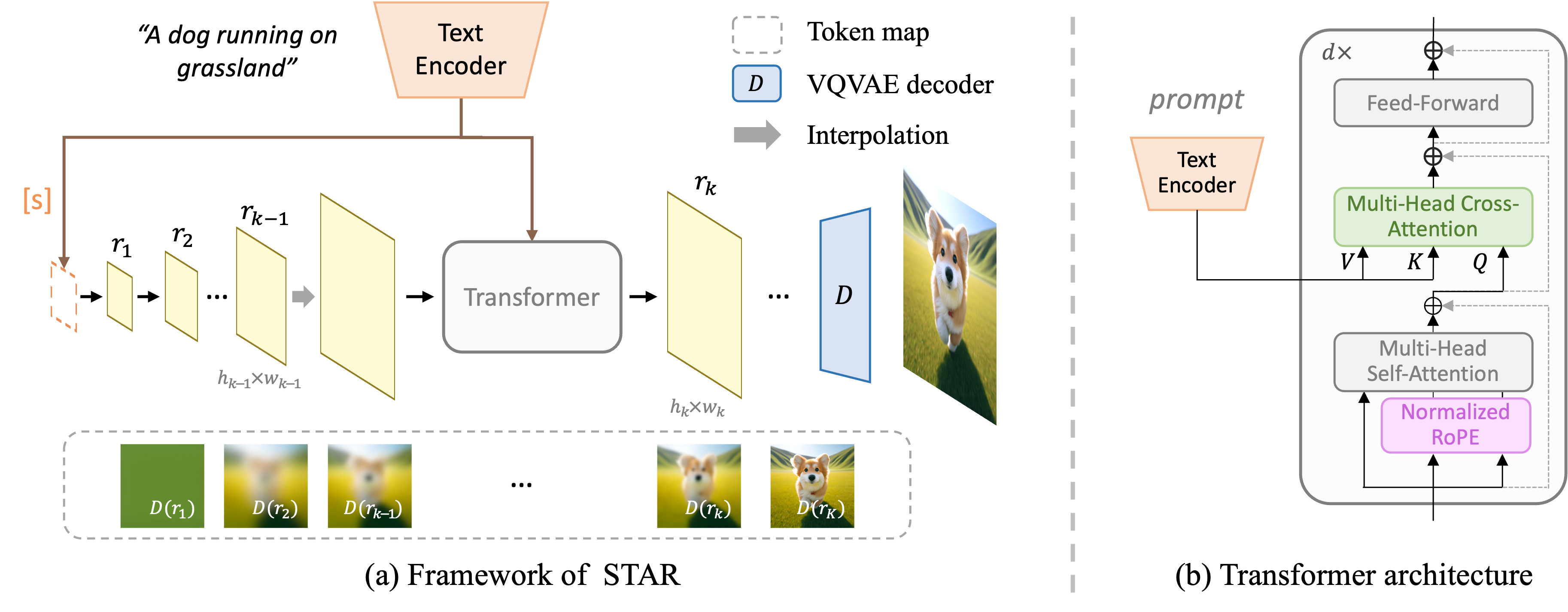
STAR is a novel scale-wise text-to-image model that is effective and efficient in terms of performance.
Notably, STAR also shows efficiency by requiring merely 2.95s to generate a 512×512 image (compared to 6.48s for PixArt-α).