
👀 About Me
Hi,
🌱 I’m Xiaoxiao Ma, a first-year PhD student at USTC, in USTC-BIVLab supervised by Prof. Feng Zhao. I am currently a research intern at Meituan
📖 My research interest includes:
- Generative models & image synthesis, autoregressive models, vision-language models
- Image restoration, image enhancement
📫 Looking forward to any collaborations or internship positions, feel free to contact me via email
🔥 News
- 2026.02: Thrilled to share that our co-authored paper MaskFocus has been accepted to CVPR 2026!
- 2026.01: Excited that our collaborative work GCPO was accepted to ICLR 2026!
- 2025.09: Delighted to announce that ARSample was accepted by NeurIPS 2025!
- 2025.06: Delighted to announce that HQ-CLIP was accepted by ICCV 2025!
- 2024.09: Delighted to announce that MPI was accepted by NeurIPS 2024!
- 2024.09: I was invited to give a talk at ByteDance as the author of STAR! See slides here
- 2024.06: STAR is now available on arXiv!
📝 Publications
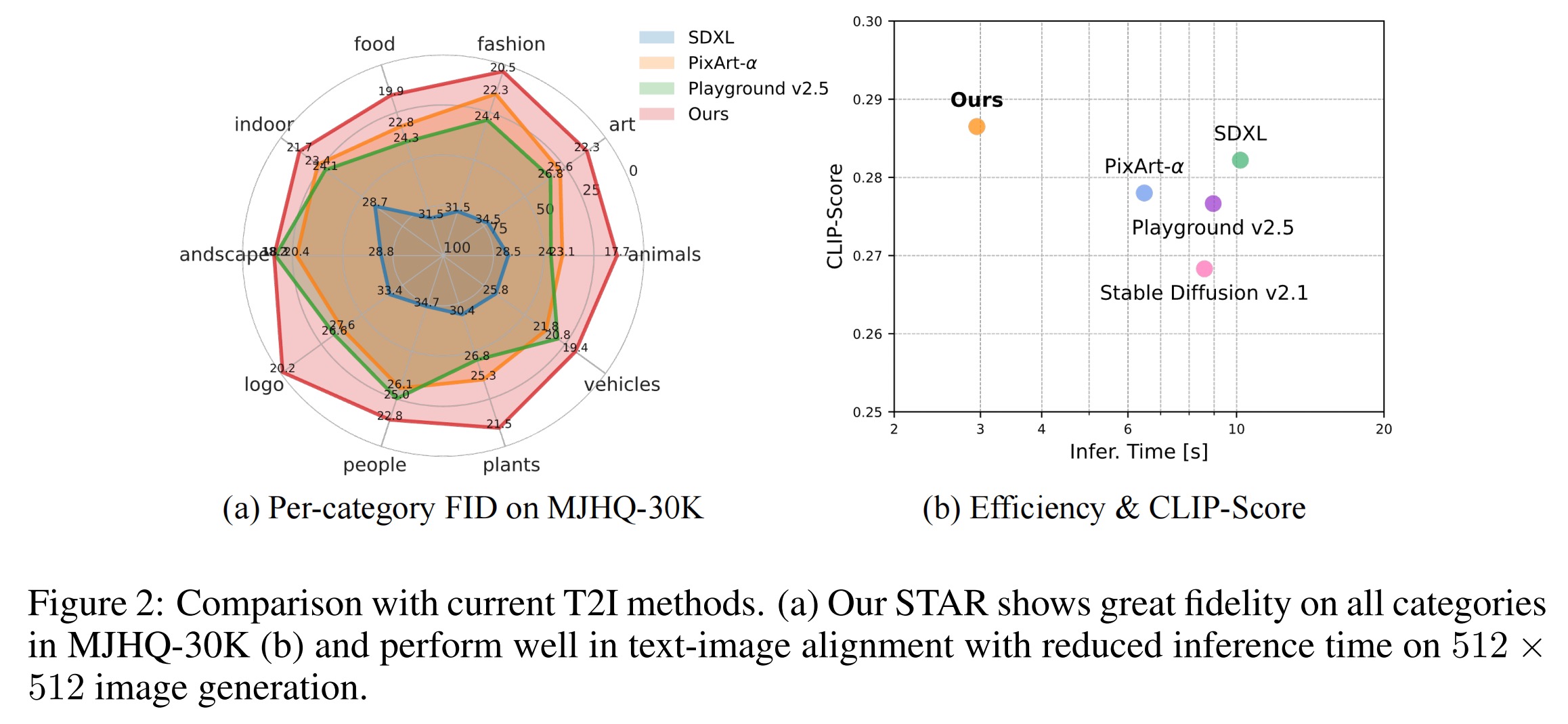
STAR: Scale-wise Text-to-image generation via Auto-Regressive representations
Xiaoxiao Ma*, Mohan Zhou*, Tao Liang, Yalong Bai, et al.
- STAR is a novel scale-wise text-to-image model that is effective and efficient in performance
- Notably, STAR shows efficiency by requiring 2.95s to generate 512×512 images (compared to 6.48s for PixArt-α)

Towards Better & Faster Autoregressive Image Generation: From the Perspective of Entropy
Xiaoxiao Ma, Feng Zhao, Pengyang Ling, Haibo Qiu, et al.
- We revisit the sampling problem in autoregressive image generation and reveal the low and uneven information density of image tokens.
- Based on this insight, we propose an entropy-informed decoding strategy that improves both generation quality and efficiency across diverse AR models and benchmarks.
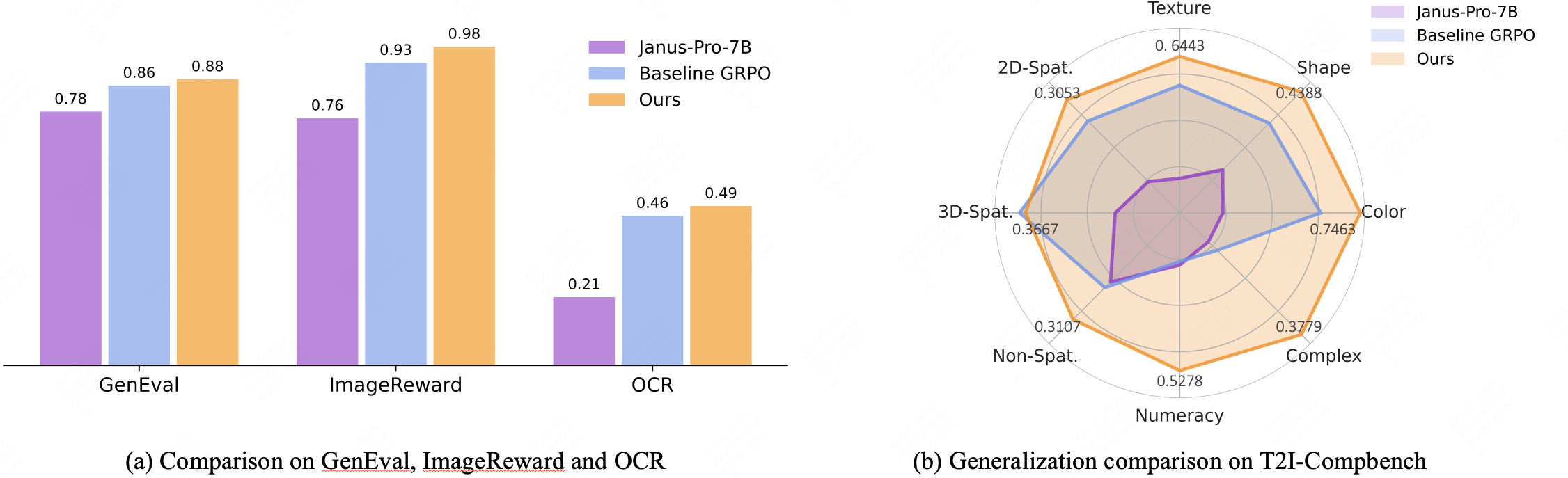
STAGE: Stable and Generalizable GRPO for Autoregressive Image Generation
Xiaoxiao Ma, Haibo Qiu, Guohui Zhang, Zhixiong Zeng, et al.
- STAGE is the first system to study the stability and generalization of GRPO-based autoregressive visual generation.
- Built upon Janus-Pro-7B, STAGE improves the GenEval score from 0.78 to 0.89 (≈14%) without compromising image quality, and its effectiveness generalizes well across benchmarks such as T2I-Compbench and ImageReward.
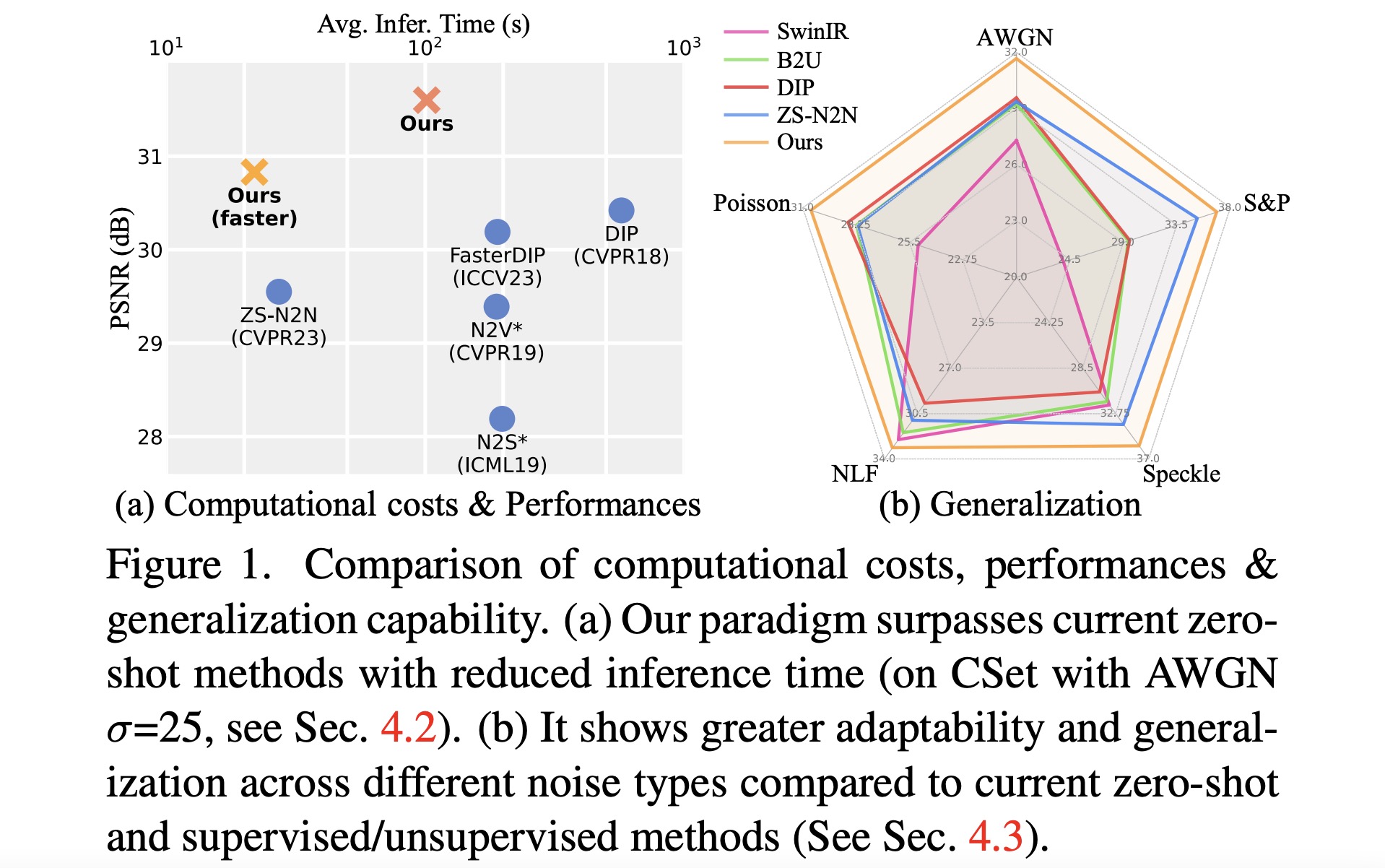
Masked Pre-trained Model Enables Universal Zero-shot Denoiser
Xiaoxiao Ma*, Zhixiang Wei*, Yi Jin, Pengyang Ling, et al.
- MPI is a zero-shot denoising pipeline designed for many types of noise degradations
- Only around 10s takes for a MPI to denoise on single noisy image

Zhixiang Wei*, Guangting Wang*, Xiaoxiao Ma, et al.
- A CLIP training framework trained on 1.3B bidirectional image–text pairs, combining bidirectional supervision and label classification, achieving SoTA zero-shot and retrieval performance.
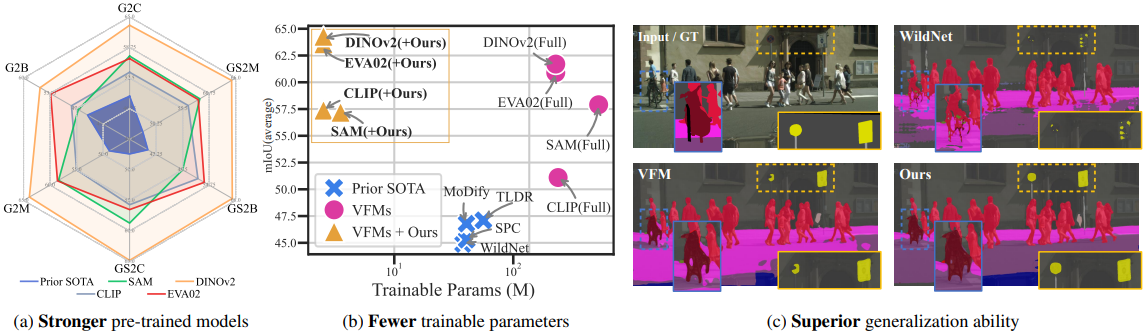
Zhixiang Wei*, Lin Chen*, Yi Jin*, Xiaoxiao Ma, et al.
- Rein is a PEFT framework based on vision foundation models for domain generalized semantic segmentation (DGSS) with merely 1% trainable parameters
💻 Experiences
- 2025.04 - Persent, Meituan LongCat Multimodal Foundation Group, Beijing.
- 2024.12 - 2025.03, OpenGVLab, Shanghai AI Laboratory, Shanghai.
- 2024.04 - 2024.12, Du Xiaoman Technology, Beijing.
📝 Academic Service (Reviewer)
- Conference Reviewer: ECCV (2026), ICML (2026), CVPR (2026), ICLR (2026), NeurIPS (2025)
- Journal Reviewer: IEEE TPAMI, IEEE JBHI
🎖 Honors and Awards
- 2022~2025 First Prize Scholarship of USTC for four continusous years
- 2024 National Scholarship for Undergraduate Students
📖 Educations
- 2025.09 - now, University of Science and Technology of China, Anhui, PhD candidate in Multimodal Learning
- 2022.09 - 2025.06, University of Science and Technology of China, Anhui, Master candidate in Computer Vision
- 2018.09 - 2022.06, China Agricultural University, Beijing. B. Eng in Computer Science